
Estava buscando projetos sobre a qualidade do ar, encontrei 3 interessantes: O painel do https://waqi.info/ que além de dados de orgãos públicos, também oferece dados de qualidade do ar de diversas fontes como o https://sensor.community e o https://www.habitatmap.org/
O https://aqicn.org/ (com sensores GAIA https://aqicn.org/gaia/list/pt/ partindo de R$271) e em https://www.aqi.in/ onde enviam um sensor com uma contribuição acima de $110.
E nisto há dois pontos diferentes: enquanto no habitatmap e aircasting.org usam dados do AirBeam (precisa adquirir o device, já pronto por $99),
Com o sensor.community é necessário comprar/instalar o hardware e configurar o firmware, DIY e opensource - via https://sensor.community/pt/sensors/airrohr/ - sinceramente, este será meu proximo projeto de fim de semana!
Adquiri 2 sensores de qualidade do ar para minha rede local (wifi, compativel com Tuya). Não possuem o mesmo objetivo que os acima.
Outro ponto: uso um app de clima, mesmo com adblock na rede (DNS com NextDNS) ele força a exibição de ads e o uso de trackers, além disto, os sites existentes estão em níveis insuportáveis.
Qual a dificuldade em ter um site de clima e outros dados ambientais sem gerar custo, ou qual o custo minimo para ter algo superior?
O que é o ClimaBR.app
O ClimaBR.app é um painel ambiental por município brasileiro. Para qualquer uma das 5.571 cidades do país ele reúne, a partir de dados públicos, a previsão do tempo, a qualidade do ar, o índice UV, o vento, o nível de reservatórios, focos de queimada e o alerta de dengue, zika e chikungunya.
A premissa de projeto é simples e rígida: consolidar dado aberto, ser acessível por máquina (AI-first) e rodar com custo zero, inteiramente dentro do free tier dos serviços envolvidos. Tudo o que descrevo abaixo cabe nos limites gratuitos, e este texto mostra exatamente quanto de cada limite o projeto consome hoje.
Um detalhe que define a personalidade do projeto: ele responde no terminal.
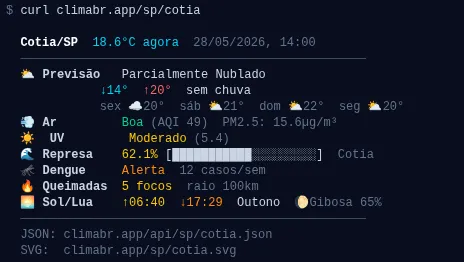
Também é possível conectar via MCP https://climabr.app/.well-known/mcp.json
Além de uma pagina para paineis e outra mobile. O objetivo é seguir com extensão no navegador e tornar o ClimaBR.app uma ferramenta completa para monitoramento ambiental até onde for possível num nível gratuito e aberto.
Arquitetura em uma imagem
GitHub (repositório + Actions)
├── Actions (cron) rodam scrapers em Python → JSON por município (commit no repo)
└── Actions fazem o build do Astro → deploy no Cloudflare Pages
Cloudflare (tudo no free tier)
├── Pages → site estático (HTML/CSS/JS gerado pelo Astro)
├── Workers → detecção de curl, formatos SVG/PNG/Prometheus, geolocalização por IP
└── DNS/SSL/WAF/Analytics → camada de borda
Navegador do usuário
└── hidrata o tempo atual e a previsão direto do Open-Meteo (sem passar por mim)A ideia central: o conteúdo é gerado estaticamente e o que é volátil (tempo agora, previsão) é atualizado no cliente, direto na fonte.
A stack de coding
Frontend: Astro em modo estático
O site é um Astro 6.4 em SSG (Static Site Generation). No build ele gera 11.172 páginas HTML (uma por município, mais o “Modo Painel” de cada cidade, mais as páginas de estado, a home e o “Modo Mobile”) e 5.598 endpoints JSON em /api/{uf}/{cidade}.json. No total são cerca de 16.792 arquivos, ~218 MB. Esse número de arquivos importa: como vou contar adiante, ele esbarra num limite concreto do Cloudflare Pages.
A camada visual usa:
- Tailwind CSS v4 (via plugin Vite), com componentes no estilo shadcn/ui e Base UI para React
- React 19 para os trechos interativos
- TypeScript em modo estrito
- lucide-react para ícones e a fonte variável Geist self-hosted (sem Google Fonts, por privacidade)
O build inteiro das 11 mil páginas leva cerca de 30 segundos.
Worker
Na frente do site roda um Cloudflare Worker em TypeScript, na rota climabr.app/*. Ele inspeciona cada requisição e decide o formato da resposta:
- Navegador: repassa para o Pages (página HTML completa)
curl/wget(detectado pelo User-Agent): devolve um painel formatado em ANSI?format=1: uma linha, ideal para tmux, i3, polybar ou prompt do shell?format=prometheus: métricas para scraping.svg: um card compartilhável.png: o mesmo card em raster, para og:image (preview em redes sociais)- raiz
/sem cidade: geolocaliza pelo IP (dado de borda da Cloudflare) e redireciona
O PNG é gerado dentro do próprio Worker com resvg compilado para WebAssembly (@resvg/resvg-wasm), que rasteriza o SVG do card. Isso evita qualquer serviço externo de imagem.
Coleta de dados: Python + GitHub Actions
Os dados vêm de scrapers em Python puro (sem dependências externas, só a biblioteca padrão), um por fonte: scrape-openmeteo.py, scrape-sabesp.py, scrape-copasa.py, scrape-dengue.py, scrape-ana.py, scrape-inpe.py, scrape-inmet.py e scrape-ondas.py. Cada um escreve em data/cidades/{uf}/{slug}.json.
Eles são disparados por cron no GitHub Actions:
- 1x/dia às 5h: previsão CPTEC (fallback)
- 1x/dia às 6h30: reservatórios da ANA e queimadas do INPE/NASA
- 1x/dia às 8h: Open-Meteo, SABESP, COPASA e dengue
- 9h e 21h, mais a cada push: build e deploy
Os dados ficam versionados no próprio repositório (cerca de 22 MB de JSON), e o deploy reconstrói o site com o snapshot mais recente.
As fontes de dados (todas públicas e gratuitas)
- Open-Meteo: previsão, índice UV, qualidade do ar, vento, nascer e pôr do sol e fase da lua
- SABESP e COPASA: nível real de reservatórios de abastecimento (SP e MG)
- InfoDengue (Fiocruz/SVS): dengue, zika e chikungunya por semana epidemiológica
- NASA FIRMS: focos de queimada (satélites NOAA-20, Suomi, MODIS)
- ONS: reservatórios do sistema elétrico
- IBGE: lista de municípios, coordenadas e malhas
- CPTEC/INPE: previsão, usada como fallback
Hidratação: estático no servidor, ao vivo no cliente
A página de cada cidade chega com um snapshot dos dados gerado no build. No navegador, um pequeno script busca a previsão e o tempo atual direto do Open-Meteo, usando o lat/lon embutido na página, e sobrescreve só os blocos voláteis. Em caso de falha, o snapshot do build permanece.
Esse desenho tem um efeito interessante de custo: a chamada ao Open-Meteo na navegação sai do navegador do usuário direto para a API, sem passar pela minha infraestrutura. Cada visitante usa a própria “cota” de rede. O Worker só consulta o Open-Meteo quando precisa montar os cards SVG/PNG, e ainda assim com cache de borda.
Duas telas de relance: Modo Painel e Modo Mobile
Além da página completa, cada cidade tem duas visões pensadas para olhar de relance, sem rolagem, cabendo numa única tela:
- Modo Painel (
/uf/cidade/telao): pensado para TV ou monitor de parede, com fundo dinâmico que muda conforme o tempo (sol, nuvem, chuva, tempestade), relógio e tiles grandes. É pré-renderizado, um arquivo por cidade. - Modo Mobile (
/mobile?c=uf/slug): a mesma ideia, mas compacto para celular, para salvar como página inicial ou virar uma extensão de navegador.
O Modo Mobile rendeu uma boa lição de arquitetura. A intenção inicial era pré-renderizar uma página por cidade, como o Modo Painel. Só que isso somaria mais 5.571 arquivos ao build e estouraria um limite do Cloudflare Pages (detalhado adiante). A solução foi inverter o desenho: o Modo Mobile é uma única página que lê a cidade da URL (?c=uf/slug), busca o JSON em /api e monta os tiles no próprio navegador, mesclando os dados ao vivo do Open-Meteo. Resultado: a feature inteira custou um arquivo em vez de 5.571.
Free tier: o que cada serviço oferece e quanto eu uso
Para cada serviço, o limite gratuito e o consumo atual do projeto.
Cloudflare Pages
- Limite: tráfego e requisições ilimitados; 500 builds por mês no CI da Cloudflare; 20.000 arquivos por deploy; 25 MiB por arquivo.
- Uso: faço deploy via
wrangler(upload direto), que não conta nos 500 builds (esse limite vale só para builds rodados na infra da Cloudflare; o meu build roda no GitHub Actions). São ~16.792 arquivos por deploy, cerca de 84% do teto de 20.000. Tráfego: irrelevante para o limite (é ilimitado). - O limite que mais incomoda: o de 20.000 arquivos por deploy. Com três variações por cidade (página, Modo Painel e JSON da API), já uso 5.571 arquivos de cada uma e fico perto do teto. Foi exatamente isso que me forçou a fazer o Modo Mobile como página única client-rendered: uma quarta variação por cidade teria estourado o limite. A lição é que, num site estático com muitas páginas, o gargalo do free tier não é banda nem build, é a contagem de arquivos.
Cloudflare Workers
- Limite: 100.000 requisições por dia; 10 ms de CPU por requisição; bundle de 1 MiB comprimido no plano free.
- Uso: o bundle está em 980 KiB gzip, cerca de 96% do limite (o peso vem quase todo do WebAssembly do resvg). As requisições diárias estão bem abaixo de 100k no estágio atual. O ponto de atenção é o tamanho do bundle: estou perto do teto, então otimizações futuras precisam respeitar essa folga apertada.
Cloudflare R2
- Limite: 10 GB de armazenamento; 1 milhão de operações de escrita e 10 milhões de leitura por mês; egress gratuito.
- Uso: zero. O R2 está habilitado na conta mas dormente - ainda não estou usando ele. Hoje os dados ficam embutidos no build; o R2 entra em cena só quando fizer sentido atualizar dado sem rebuild.
Outros recursos Cloudflare (todos no free)
- Web Analytics (RUM): métricas de visita sem cookies, alimentadas por um beacon JavaScript. Grátis e ilimitado.
- DNS, SSL/TLS, DDoS, HTTP/3, 0-RTT, Tiered Cache, DNSSEC: incluídos.
- WAF: o conjunto gerenciado gratuito, mais uma regra de rate limiting (por IP).
- Page Shield: monitoramento de scripts (o inventário client-side é grátis; a detecção de script malicioso é paga).
GitHub
- Limite: Actions com 2.000 minutos por mês em repositório privado, e ilimitado em repositório público.
- Uso: com o repositório público, o Actions é gratuito e ilimitado, então esse limite deixou de existir. A história até chegar aqui é instrutiva: enquanto o repo era privado, a fatura mostrava 404 minutos em apenas 2 dias, uma projeção de ~6.000/mês, três vezes o teto gratuito. O culpado eram crons frequentes demais (a coleta CPTEC rodava a cada 3 horas, a da ANA a cada 6). Fiz duas coisas: reduzi todos os crons para 1x/dia (já que reservatório, queimada e previsão não mudam de hora em hora) e tornei o repositório público. Qualquer uma resolveria; juntas, sobra folga.
APIs de dados
- Open-Meteo: gratuito para uso não comercial, sem chave, com limites de uso justo de cerca de 10.000 chamadas por dia e 600 por minuto. Esse foi o limite mais sutil do projeto. Uma passada completa pelas 5.571 cidades, em duas APIs (previsão e qualidade do ar), passa de 10.000 chamadas, ou seja, não cabe numa coleta diária única. A solução foi tornar a coleta no servidor incremental: cada rodada atualiza primeiro as cidades mais desatualizadas e pula as que foram coletadas nas últimas horas, ciclando por todas em um a dois dias. O detalhe que salva a experiência do usuário é a hidratação: como o navegador chama o Open-Meteo direto, cada visitante usa a própria cota, e a página fica sempre ao vivo independente do ritmo da coleta no servidor.
- InfoDengue, NASA FIRMS, IBGE, ONS, SABESP, COPASA, CPTEC: APIs e arquivos públicos, sem chave e sem cobrança.
Armadilhas que aprendi no caminho
Alguns problemas reais que apareceram e que valem como aprendizado:
1. Content Security Policy bloqueando silenciosamente. A CSP estrita do site bloqueou, em dois momentos diferentes, o fetch da hidratação ao Open-Meteo e depois o beacon do Web Analytics. O sintoma é traiçoeiro: nenhum erro visível, a feature simplesmente não funciona. A lição: toda vez que se adiciona algo que carrega script externo ou faz fetch externo, é preciso atualizar a allowlist da CSP (script-src/connect-src), e validar em um navegador real.
2. resvg sem fonte gera PNG em branco. O resvg em WebAssembly não tem fontes de sistema. Sem carregar um buffer de fonte, ele renderiza só as formas vetoriais e nenhum texto, ou seja, o card PNG saía com o layout e sem dado nenhum. A correção foi embutir um subset mínimo de fonte (cerca de 28 KB gzip, respeitando o limite de 1 MiB do Worker) e, como o resvg também não renderiza emoji colorido, trocar os ícones por formas vetoriais no PNG.
3. Injeção automática de analytics não funciona atrás de um Worker. O beacon que a Cloudflare injeta sozinho no HTML é instável quando a resposta é servida por um Worker. A solução foi injetar o beacon manualmente no layout do Astro.
4. Card com dado estático enquanto a página estava ao vivo. Os cards SVG/PNG eram montados só a partir do JSON estático, então ficavam atrasados em relação à página, que hidrata ao vivo. Passei a buscar o Open-Meteo também no Worker ao montar o card, com cache curto.
5. Um marcador de “já processado” que congelou os dados. Para respeitar o rate limit, a coleta do Open-Meteo pulava cidades já processadas, checando a presença de um campo. Só que o campo era permanente: depois da primeira coleta, todas as cidades passavam a ser puladas para sempre, e a previsão congelou numa data. A correção foi trocar o critério por data de coleta (recolhe se passou de N horas), e não pela mera existência do campo. De quebra, ao tentar acelerar com lotes de 100 coordenadas, estourei o limite de 600 chamadas/minuto e tomei uma enxurrada de erros 429: o ritmo certo é tão importante quanto a lógica.
6. CSS escopado do Astro versus HTML gerado por JavaScript. O Astro, por padrão, escopa o CSS de cada componente (adiciona um atributo aos elementos e restringe os seletores a ele). O Modo Mobile monta os tiles via innerHTML no cliente, em runtime, e esses elementos não recebem o atributo de escopo, então o CSS simplesmente não se aplicava: a tela vinha com as informações sobrepostas, sem as caixas. A correção foi marcar o estilo como global (<style is:global>). A lição mais ampla: o que é renderizado no cliente vive fora do sistema de escopo do framework.
Custo total
Zero de operação. O único gasto recorrente é a renovação anual do domínio .app. Todo o resto, hospedagem, edge computing, coleta de dados, analytics e segurança, cabe nos planos gratuitos descritos acima.
Encerramento
O ClimaBR.app mostra que dá para entregar um serviço público útil, com cobertura nacional e várias fontes de dado, sem custo de infraestrutura, desde que o desenho respeite os limites gratuitos desde o início: estático onde der, edge para o que diferencia, coleta agendada e dado aberto. O código é open source sob AGPL-3.0.